'속도'를 고려하며 쿼리를 작성하고 검증하기
들어가기에 앞서 🔍
ORM은 개발자들에게 매우 편리한 수단입니다. 어플리케이션 개발 언어로 SQL을 작성해준다고? 완전 개꿀이죠! 하지만 DBA분들에게 ORM은 꽤나 실무에서 골칫덩이라고 합니다. 데이터베이스 성능을 저하시킬 수 있는 가능성이 있기 때문이죠.
ORM을 잘 사용하는 것. 개발 생산성에 매우 지대한 영향을 미치기 때문에 중요한 요소입니다. 하지만 그것보다 더 중요한 것은 ORM의 기저에 깔려있는 ‘근본’ SQL 아닐까요?
그래서 이번 포스트에서는 특정 시나리오 상황에서 같은 결과를 도출하는 두가지 쿼리를 비교하고 성능을 분석해보려고 합니다.
1. 시나리오 가정
1) 요구사항
특정 게시물에 달린 댓글들의 List를 받아옵니다. (대댓글x) 이 때, 반환되는 댓글들 List의 원소들, 즉 댓글 한개마다 로그인한 유저가 ‘좋아요’를 했는지 아닌지 알 수 있는 쿼리를 작성해주세요.
- comment.info 테이블
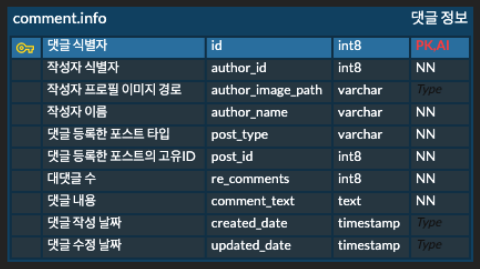
comment.info 테이블 정보입니다
- member.like_comment 테이블
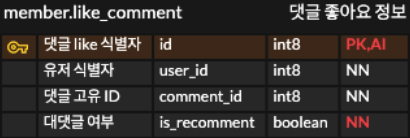
comment like 테이블 정보입니다
- 상황 가정
- 어떠한 테이블도 FK를 가지고 있지 않습니다. (update, delete를 하지 않기 때문에 요구상황을 구현하는데 신경쓰지 않아도 됩니다. 시나리오를 위한 세팅 또한 무결성을 해치지 않게 구성하였습니다.)
- 게시물의 타입은 두가지입니다. (‘BLOG’ , ‘QUESTION’)
- 게시물의 타입별 post_id는 해당 게시물 타입에서 유일합니다.
- comment의 수는 포스트 타입별로 100만개, 등록된 유저의 수도 100만명이라고 가정합니다.
- member.like_comment에 등록된 row의 개수는 100만 + 1개입니다. (유저별로 한개의 댓글을 좋아요했다고 가정. 왜 100만 + 1개냐구요? 8번 상황을 고려하기 위해서 하나 더 추가한 row입니다.)
- post type ‘BLOG’ 의 ‘1’번 게시글에 해당하는 댓글 리스트를 가져옵니다.
- 로그인한 사용자의 user_id 는 ‘1’ 이라고 가정합니다.
- user_id ‘1’의 사용자는 ‘BLOG’의 ‘1’번 게시글의 댓글중 좋아요한 댓글이 적어도 한개 있습니다.
2) 시나리오 세팅
1. comment.info 테이블
--- schema 생성 ---
CREATE SCHEMA comment;
--- table 생성 ---
CREATE table comment.info (
id serial4 primary key,
author_id int8 NOT NULL,
author_image_path varchar(300) NULL,
author_name varchar(15) NOT NULL,
post_type varchar NOT NULL,
post_id int8 NOT NULL,
recomments int8 NOT NULL DEFAULT 0,
comment_text text NOT NULL,
created_date timestamp NULL DEFAULT CURRENT_TIMESTAMP,
updated_date timestamp NULL DEFAULT CURRENT_TIMESTAMP
);
2. member.like_comment 테이블
--- schema 생성 ---
CREATE SCHEMA member;
--- table 생성 ---
CREATE TABLE member.like_comment (
id serial4 primary key,
user_id int8 NOT NULL,
comment_id int8 NOT NULL,
is_recomment bool NOT NULL,
CONSTRAINT unique_columns UNIQUE (user_id, comment_id, is_recomment)
);
3. table에 정보를 insert 해봅시다.
100만개의 data를 table에 insert하는 방법은 많겠지만, python을 이용한 간단한 script로 insert를 해봅시다.
# Comment 정보 저장
import psycopg2
from psycopg2 import extras
import random
# PostgreSQL 데이터베이스 연결 설정 (개별적으로 다르게 설정하시면 됩니다.)
conn = psycopg2.connect(
host="localhost",
database="postgres",
user="",
password=""
)
# 커서 생성
cursor = conn.cursor(cursor_factory=extras.RealDictCursor)
# 무작위 post_id 생성 함수
def generate_random_post_id():
return random.randint(1, 1000001)
# 100만개의 데이터를 생성하여 삽입하는 예시
for i in range(1, 1000001):
cursor.execute("INSERT INTO comment_info (author_id, author_name, post_type, post_id, comment_text) VALUES (%s, %s, %s, %s, %s)",
(i, '테스트' + str(i), 'BLOG', generate_random_post_id(), '테스트 댓글입니다'))
cursor.execute("INSERT INTO comment_info (author_id, author_name, post_type, post_id, comment_text) VALUES (%s, %s, %s, %s, %s)",
(1000001 - i, '테스트' + str(1000001 - i), 'QUESTION', generate_random_post_id(), '테스트 댓글입니다'))
# 변경 내용을 커밋
conn.commit()
# 커넥션과 커서 닫기
cursor.close()
conn.close()
최대한 실제와 유사한 상황을 만들기 위해서, 무작위의 post id에 댓글을 작성하는 상황을 가정해보았습니다. 그럼 ‘BLOG’ 타입, ‘QUESTION’ 타입의 포스트에 각각 100만개의 댓글이 작성됩니다. 이 때, comment.info.id는 like_comment 테이블의 comment_id 와 동일합니다.

랜덤으로 생성했지만, 운이 좋았죠?
random으로 생성했는데, 우연히 요구사항에 맞게 post_id 가 1이고, post_type이 ‘BLOG’인 댓글이 두개가 존재하네요! (없으면 임의로 insert해서 생성해보도록 합시다) 이 id를 like_comment 테이블에서 user_id가 1인 친구가 1095,567번의 comment_id 를 좋아한다는 정보를 추가해야하는 사실을 잊지 맙시다.
# like 정보 저장
import psycopg2
from psycopg2 import extras
import random
# PostgreSQL 데이터베이스 연결 설정
conn = psycopg2.connect(
host="localhost",
database="postgres",
user="",
password=""
)
# 커서 생성
cursor = conn.cursor(cursor_factory=extras.RealDictCursor)
# 무작위 post_id 생성 함수
def generate_random_post_id():
return random.randint(1, 1000001)
# 100만개의 데이터를 생성하여 삽입하는 예시
for i in range(1, 1000001):
cursor.execute("INSERT INTO member.like_comment (user_id, comment_id, is_recomment) VALUES (%s, %s, %s)",
(i, generate_random_post_id(), False))
# 요구사항 8번에 맞게 정보 insert
cursor.execute("INSERT INTO member.like_comment (user_id, comment_id, is_recomment) VALUES (%s, %s, %s)",
(1,1095567,False))
# 변경 내용을 커밋
conn.commit()
# 커넥션과 커서 닫기
cursor.close()
conn.close()
그럼 준비는 끝났습니다 !
2. 쿼리 작성하기
작성시 고려해야할 사항은 다음과 같습니다.
post_type이 ‘BLOG’ 이면서 post_id ‘1’ 을 가지고 있는 게시글에 등록된 댓글들을 조회해야 한다. 👉
SELECT, WHERE조회한 댓글 중에서, 로그인한 유저가 좋아요한 댓글인지 확인하기 위해서 member.like_comment (이하 별칭 L) 테이블과 comment.info(이하 별칭 C)테이블에서 같은 comment id를 가지는 댓글들을 가져온다. 👉
C LEFT JOIN L(그냥 (INNER) JOIN을 사용하면 좋아요한 댓글 정보만 남습니다.)가져온 댓글들 중에서 로그인한 유저가 좋아요를 했는지 확인하는 과정을 거쳐, 좋아요를 눌렀으면 댓글마다 isLike 필드에 true를, 아니면 false를 반환한다 👉
SELECT 에 열을 추가 및 대댓글 아닌것만 필터링
이정도로 생각해볼 수 있을것 같습니다. 저대로 쿼리를 작성하면 어떻게 될까요?
SELECT
C.id,
C.author_id,
C.author_image_path,
C.author_name,
C.re_comments,
C.comment_text,
C.created_date,
C.updated_date,
CASE WHEN L.user_id = 1 THEN TRUE ELSE FALSE END AS is_liked -- 로그인된 사용자가 좋아요를 했는지 확인하는 부분
FROM comment.info C
LEFT JOIN member.like_comment L ON
C.id = L.comment_id
AND L.user_id = 1
AND L.is_recomment = false
WHERE C.post_type = 'BLOG'
AND C.post_id = 1
ORDER BY C.created_date;
이런 쿼리가 만들어졌습니다.
근데 여기서 한가지 마음에 걸리는 부분이 있습니다. JOIN되는 두가지 테이블의 데이터가 너무 많아지게 된다면, JOIN 연산을 하는데에 너무 많은 비용이 들 것 같습니다. comment 의 row 수는 200만개이고, like_comment의 row 수는 100만개인데 JOIN을 하게되면 200만 * 100만의 시간복잡도를 가질 것으로 예상했습니다.
그렇다면, join연산에 들어가는 데이터의 양을 줄이는 것이 가장 필요해보입니다. 그러기 위한 방법으로 서브쿼리를 활용해보았습니다.
SELECT
C.id,
C.author_id,
C.author_image_path,
C.author_name,
C.recomments,
C.comment_text,
C.created_date,
C.updated_date,
CASE WHEN L.user_id = 1 THEN TRUE ELSE FALSE END AS is_liked
FROM (
SELECT
id,
author_id,
author_image_path,
author_name,
recomments,
comment_text,
created_date,
updated_date
FROM comment.info
WHERE post_type = 'BLOG'
AND post_id = 1
) C
LEFT JOIN member.like_comment L
ON C.id = L.comment_id
AND L.user_id = 1
AND L.is_recomment = false
ORDER BY C.created_date;
이렇게 하면 FROM절 내부 서브쿼리에서 post_type 이 ‘BLOG’이면서 post_id가 1인 comment정보를 미리 추리고, like_comment 테이블과 join을 하게됩니다. 그러면 시간복잡도는 (서브쿼리로 정보를 필터링하는 비용 200만 + post_type 이 ‘BLOG’이면서 post_id가 1인 게시글의 댓글 수 * 100만) 이 될 것입니다.
따라서 서브쿼리를 사용하지 않을 때는 200만 x 100만의 시간복잡도라면, 서브쿼리로는 200만 + 100만 x 상수 정도의 매우 작은 시간복잡도를 가지게 됩니다.
과연 결과도 그러할까요?
3. 쿼리 속도 측정 방법
쿼리가 얼마나 걸리는지 속도를 측정하려면 어떻게 해야할 까요?
PostgreSQL 에서는 EXPLAIN 명령어를 지원합니다.
https://www.postgresql.org/docs/current/using-explain.html
위 공식내용을 약간 정리하겠습니다.
1. Query Plan
RDBMS는 대부분 쿼리 계획을 수립하고 최적화하기 위한 복잡한 기능을 포함하고 있습니다. 이를 통해 주어진 쿼리에 대해 최적의 실행 계획을 선택하고 데이터에 효율적으로 액세스할 수 있습니다. 이러한 실행 계획을 분석하는 명령어가 ‘EXPLAIN’ 입니다.
Query Plan의 구조는 plan node로 이루어진 tree 구조입니다. 이때 가장 하위에 있는 leaf node들은 scan node입니다. 이러한 scan node에서 순차 스캔(sequential scans), 인덱스 스캔(index scans) 등등의 작업이 일어납니다.
해당 작업이 일어난 후에, 스캔 작업의 결과물을 처리하기 위한 또다른 작업이 필요할 수도 있습니다. 예를들어, 집계함수를 사용 한다거나, 다른 테이블과의 JOIN, sorting 작업이 그러한 경우입니다. 이러한 작업들은 scan node 상위 node에서 처리합니다. 그리고 또 그 상위 노드에서 처리가된 노드를 그 상위 노드에서 다시 가공할 수도 있습니다. 물론 그게 끝일 수도 있습니다.
이렇게 tree 구조로 query plan이 만들어지고, 상위노드의 작업은 하위 노드의 성능을 모두 포함하게 됩니다.
그래서 결국 DBMS는 최상위 노드의 cost값이 최소인 query를 선택합니다. 그리고 우리는 이 cost값을 줄이기 위해 노력해야 합니다.
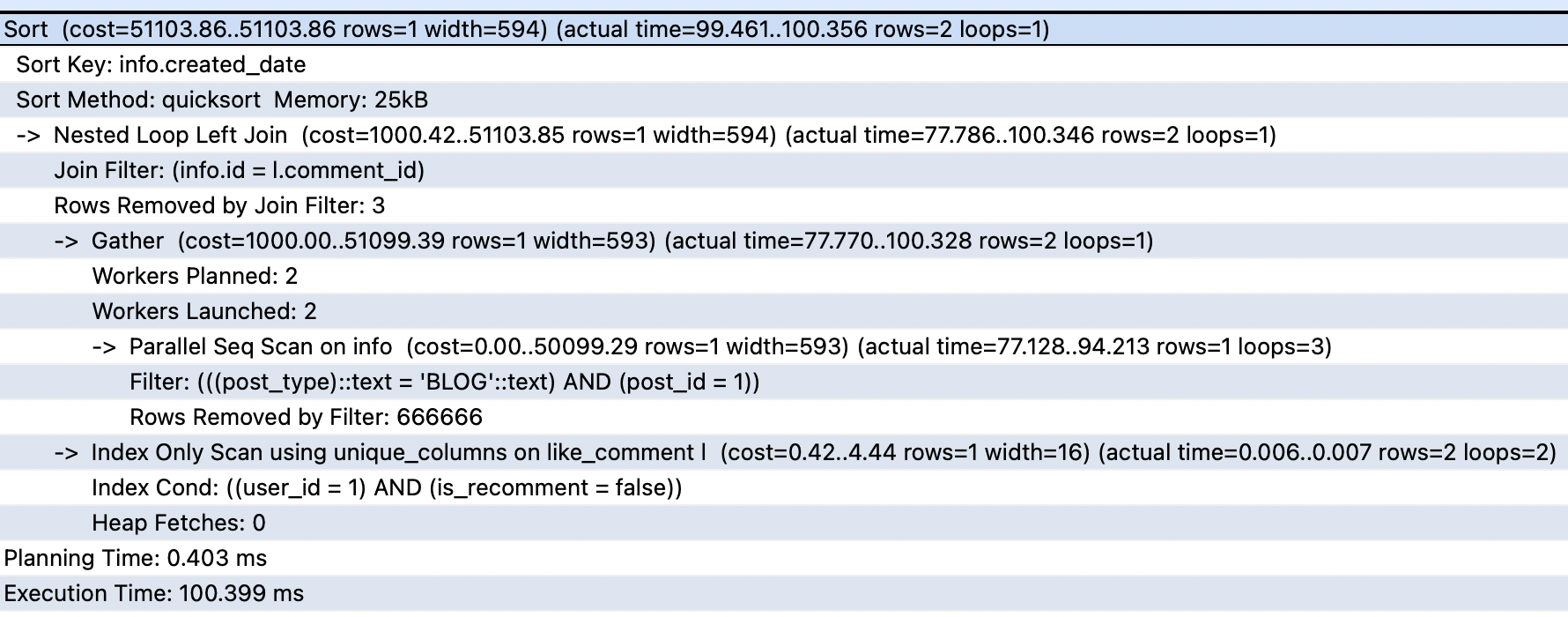
query plan의 예시 사진입니다.
위 사진에서 맨 윗줄이 해당 쿼리의 총 cost입니다.
indent 가 되어있는 부분은 해당 node의 속성을 말합니다.
->처리가 되어있는 부분은 하위 node를 의미합니다. 그러면 위의 query plan에서는 어떤일이 일어나는지 하위 노드부터 정리하겠습니다.Parallel Sequential Scan 작업 (병렬처리)
-1. 1번 작업의 병렬 처리 작업을 하기 위해 Gather 노드가 포함된 계획을 자동으로 생성 및 처리
-2. index scan을 통해 row 1개를 가져옴
Nested Loop Left Join을 통해 2-1 과 2-2 작업의 결과를 join created_date 조건에 맞게끔 sorting
최종 실행 결과 분석
( cost는 시간이 아니라, I/O, CPU 할당과 같은 작업 비용을 말합니다. )
예상 시작 비용 : 51103.86
이는 마지막 출력 단계가 시작되기 전에 소요된 비용으로, sorting 비용을 의미합니다.
예상 총 비용 : 51103.86
이는 모든 노드의 작업이 완료될 때까지 실행된다는 가정하에 걸린 시간입니다.
최종 row 수 : 1
이 계획 노드에 의해 출력되는 행의 예상 수입니다. 다시 말해, 노드가 완료될 때까지 실행된다는 가정하에 계산됩니다. ‘예상’이기 때문에 실제와 다를 수 있습니다.
총 바이트 : 594
이 계획 노드에 의해 출력되는 행의 예상 평균 너비(바이트 단위)입니다.
뒤의 actual time은 EXPLAIN ANALYZE 명령어의 도출값으로, 실제 걸린 시간과, 반환된 row수를 의미합니다.
2. EXPLAIN vs EXPLAIN ANALYZE
EXPLAIN : 쿼리 계획 예상 결과를 나타냅니다.
EXPLAIN ANALYZE : 직접 쿼리를 실행해보고, 걸린 시간과 반환 행 수를 나타냅니다. ‘직접 쿼리를 실행’하기 때문에, DB에 변경사항이 생길 수 있다는 점을 반드시 기억하셔야 합니다.
4. 두가지 쿼리의 실행 결과 분석
JOIN만 사용한 경우 join 사용 query 결과입니다.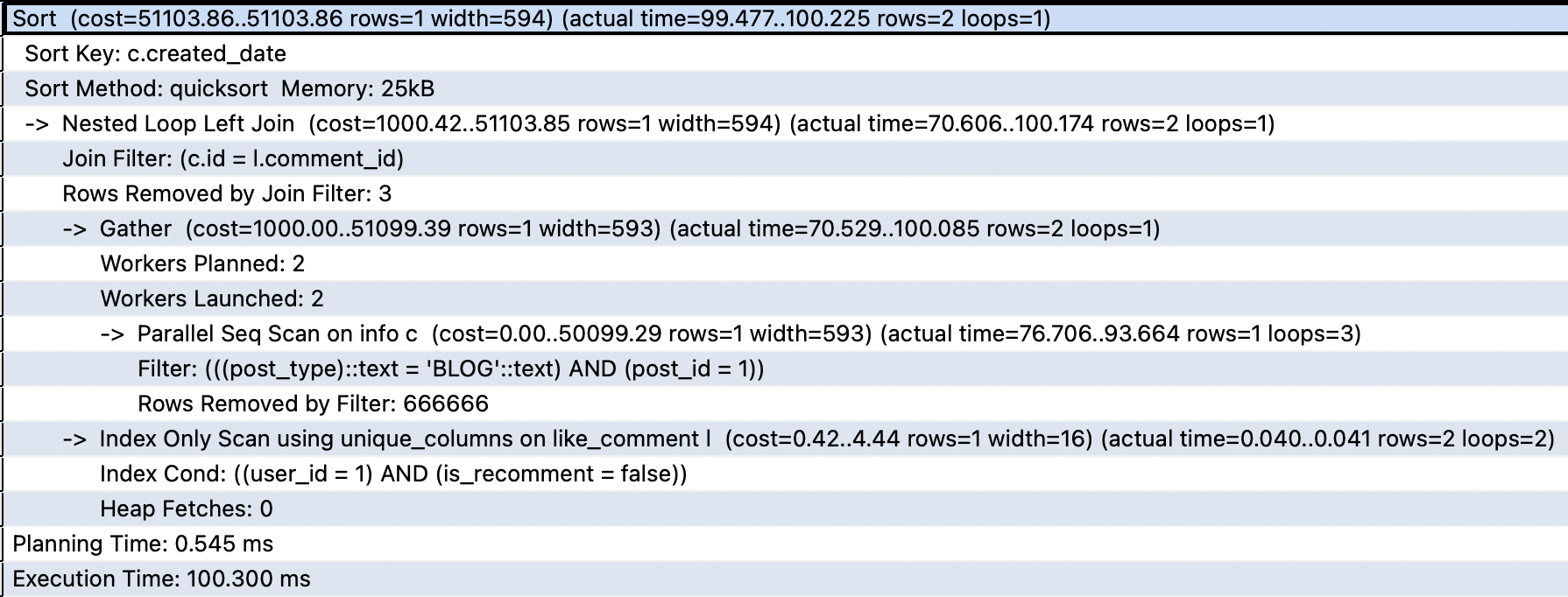
서브쿼리를 사용한 경우 sub query 사용 쿼리 결과입니다.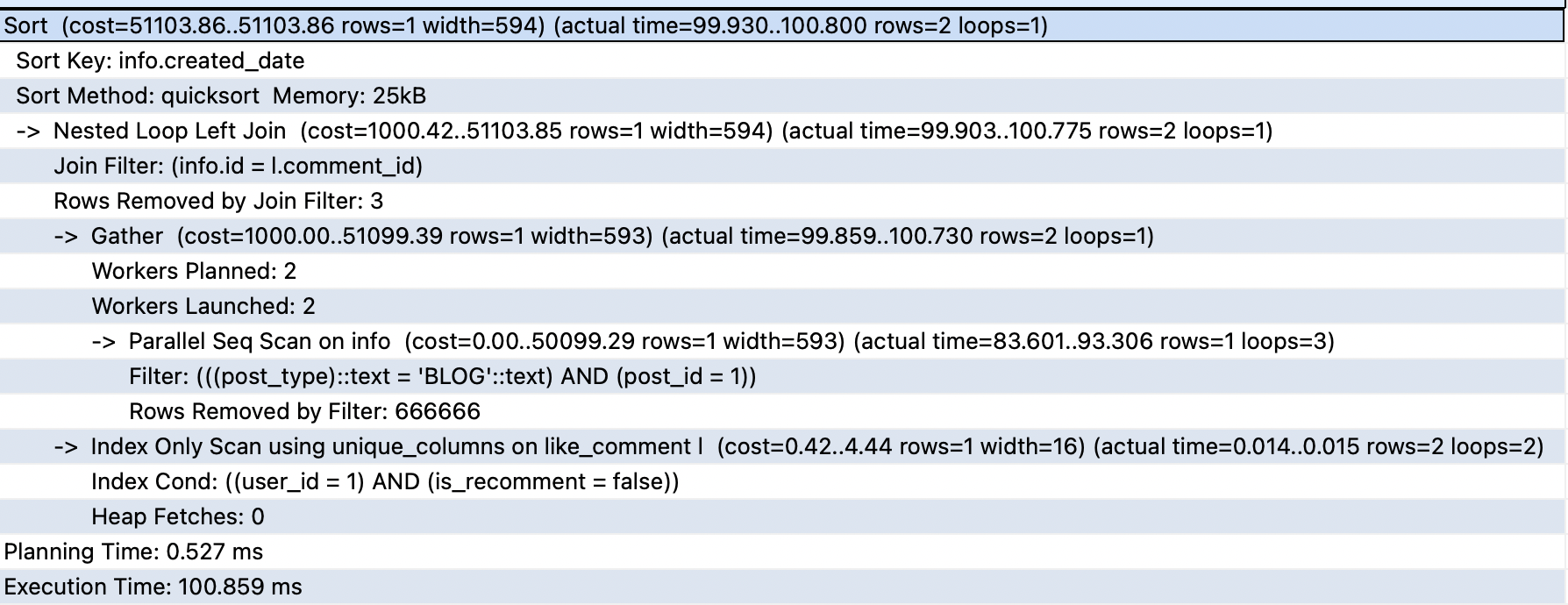
5. 정리
여러분들도 저와 같이 당연히 subquery를 사용하는것이 더 빠를 것이라고 예상하셨는지 모르겠습니다. ‘혹은 서브쿼리를 사용하는 것이 안좋다.’ 라고 막연하게 이해하셨던 분들도 계실 것 같습니다.
내가 작성한 쿼리가 DBMS 안에서 어떠한 과정으로 결과를 도출해내는지 직접 검증을 통해, 앞으로 작성할 쿼리에 대해 ‘속도’를 고려하면서 작성 및 검토 해보셨으면 좋겠습니다.